linode 新加坡机房太慢原因分析与带宽优化建议

本文先概述常见导致云主机访问缓慢的几类原因,并给出可复现的检测步骤与分层优化建议,便于快速定位瓶颈并采取短期与长期的带宽优化措施。
为什么 linode 新加坡机房 会感觉很慢?
访问变慢通常由三大类因素叠加:一是链路与互联(ISP互联/Peering)问题,二是实例或上游带宽限速与共享资源争用,三是应用层或TCP配置不佳。具体表现为高延迟、丢包或带宽无法饱和。特别是跨国访问时,若中间运营商对特定路由存在差异化限速或欠佳Peer关系,就会出现稳定性差与吞吐低的情况。
哪里最可能是网络瓶颈,怎么判断?
瓶颈通常出现在三处:用户到最近出口ISP(最后一公里/链路),国际出口与中转(ISP互联点),以及Linode的上游骨干或虚拟化网卡。判断方法:在本地和远端分别使用 mtr -r -c 100 <服务器IP>、traceroute -T <服务器IP>、iperf3 -c <服务器IP> -P 10 来测延迟、丢包与吞吐;在服务器端运行 iperf3 -s、ss -s、ifconfig 或 ip -s link 查看网卡错误/丢包并用 ethtool -S eth0 查看统计。如果中间跃点出现大量丢包或突增RTT,说明链路或Peering问题;若到最后一跳丢包或CPU/中断占用高,则可能是实例配置或主机端限制。
怎么系统性做性能定位与测试?
建议按顺序做:1) 本地->服务器 iperf3 测试(多线程 -P 10),记录带宽和延迟;2) mtr/trace 定位哪个跃点丢包或延迟突增;3) 服务器端 ss -s、top/htop、dmesg 检查CPU/中断与驱动问题;4) 检查网络队列与qdisc,tc -s qdisc;5) 若怀疑MTU问题,用 ping -M do -s 1472 <目标> 测试分片;6) 如要复现持续高流量,使用 iperf3 -P N 并观察是否能线性增长。保存命令输出并在发工单时一并提供。
哪些服务器与内核参数能快速带来 带宽优化 效果?
优先级较高的调整包括启用现代拥塞控制和调度器:sysctl -w net.core.default_qdisc=fq net.ipv4.tcp_congestion_control=bbr;并增大缓冲区:sysctl -w net.core.rmem_max=16777216 net.core.wmem_max=16777216 net.ipv4.tcp_rmem="4096 87380 16777216" net.ipv4.tcp_wmem="4096 65536 16777216"。确保内核支持 BBR(需要 Linux 4.9+),并在测试前重启网络或重载模块。对高并发短连接场景,可适当增大 net.ipv4.tcp_max_syn_backlog 与 file descriptor 限额。
怎么在网络接口与虚拟化层面做优化?
检查是否启用了网卡多队列与硬件卸载(ethtool -l / -k),对虚拟化环境可启用 SR-IOV 或 Virtio 网络驱动的多队列支持以减少中断争用。必要时调整 GRO/TSO/GSO(ethtool -K eth0 gro on tso on gso on),如果出现异常数据包合并导致问题,可短期尝试关闭这些功能以排查。对于高带宽需求,可选更高规格实例或绑定私有网络与浮动IP以减少公网上的波动。
哪个架构或产品更适合不同场景的优化需求?
短期:优先通过CDN(例如 Cloudflare)或在新加坡与目标用户更接近的边缘节点缓存静态资源,能立刻减轻Linode实例出口压力。中期:调整实例规格、选择支持更好带宽保障的计划或在同一区域部署多实例并使用负载均衡。长期:评估是否需要更优的互联(直接购买到目标ISP的专线或使用合作伙伴互联),或迁移到在目标市场具有更好Peer关系的数据中心(如东京、孟买或香港,视目标用户地理而定)。
怎么向 Linode 提交有效工单以加速问题解决?
提交前准备好:1) 问题描述与时间窗;2) mtr/traceroute/iperf3 的原始输出;3) ifconfig/ip link、ss -s、top、dmesg、ethtool -S 的摘录;4) 受影响实例ID、数据中心(Singapore)与测试目标IP。工单中指出已排除了本地ISP与应用层问题并请求运营商层面路由/peering检查。Linode 支持通常会在网络层面执行 BGP 路由检查与上游链路探测。
-

在新加坡电梯机房部署关键业务的风险防范与备份策略
要点速览 在新加坡电梯机房部署关键业务时,需综合考虑物理风险与网络风险,建立多层备份与冗余。核心措施包括物理隔离与电力冗余、网络链路多样化、基于 服务器 与 VPS 的异地热/冷备、利用 CDN 与专业 DDoS防御 服务进行前端保护、以及对 域名 与访问控制的严格策略。持续的监控、定期演练与落实标准化运维流程是确保业务连续性的关键。推荐德讯电2026年5月8日 -

探索新加坡高防服务器的优势与应用场景
1. 新加坡高防服务器的定义 新加坡高防服务器是专门设计来抵御各种网络攻击的服务器,尤其是在DDoS攻击方面表现突出。 这些服务器通常配备了高性能的硬件及先进的防护技术,以确保业务的稳定性和安全性。 通过采用多种防御策略,新加坡高防服务器能够有效减轻或阻止恶意2025年12月4日 -

监控与告警机制确保美国机房断网新加坡机房 时快速响应
监控与告警:让断网不再成为灾难 1. 精华:通过主动监控与合成监测实现秒级故障发现;2. 精华:基于多级告警与自动化切换缩短恢复时间;3. 精华:建立完善的演练与溯源机制,保障SLA与合规。 在全球分布的服务中,美国机房出现断网时对位于亚洲的新加坡机房既是威胁也是机会。正确的策略不是被动等待,而是通过高质量的监控和合理的告警机制做到秒级响应2026年7月5日 -

新加坡机房服务器有哪些?
新加坡机房服务器有哪些? 新加坡作为亚洲的科技中心,拥有先进的数据中心和服务器设施。新加坡机房通常位于地理位置优越、网络环境稳定、供电可靠的地区,为企业提供高质量的托管服务。 新加坡机房提供多种类型的服务器,包括: 共享服务器:适用于小型网站和个人博客,价格低廉,资源共享。 虚拟私人服务器(VPS):提供独立的2025年6月3日 -

美国和新加坡服务器推荐: 如何选择最适合您的服务器?
美国和新加坡服务器推荐: 如何选择最适合您的服务器? 在选择服务器时,很多人会纠结于美国和新加坡这两个热门的服务器地点。本文将为您介绍美国和新加坡服务器的优劣势,以及如何选择最适合您的服务器。 美国作为全球最大的互联网市场之一,拥有众多数据中心和服务器提供商。美国服务器的优势在于网络速度快、稳定性好、价格相对较低。如果您的目2025年5月26日 -
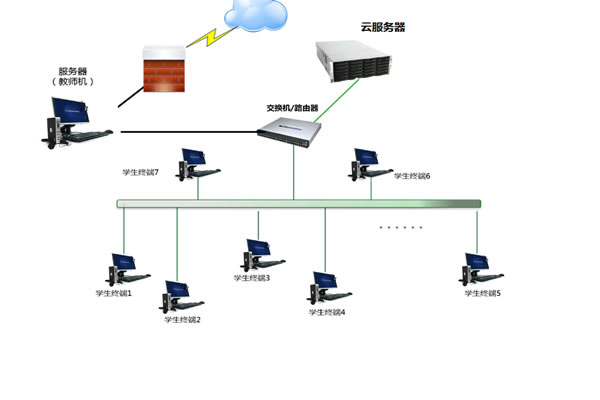
按需定制视角 新加坡高防服务器价格表如何估算定制成本
1. 概述:为什么要按需定制新加坡高防服务器 • 新加坡作为亚太网络枢纽,延迟低、出口带宽好,适合对外服务节点部署。 • 高防服务器不仅关注硬件,更关注DDoS防护层与清洗策略的组合。 • 按需定制能在性能与成本间找到平衡,避免无谓浪费固定费用。 • 成本估算必须把硬件、带宽、防护、IP、运维与许可都考虑在内。 • 本文以新加坡市场为例,分项列2026年4月18日 -

国际化企业服务器托管新加坡提升访问速度与合规性的实践
对于面向亚太和全球市场的国际化企业来说,选择新加坡作为服务器托管节点,能同时兼顾低延迟、稳定性与法规可控性。本文将围绕“最好、最佳、最便宜”的托管选项对比,提供实践建议,帮助企业在速度与合规性之间取得平衡。 在新加坡有三类常见方案:最好(高端托管/专用机房+混合云)、最佳(云服务或管理型裸金属)和最便宜(VPS/共享托管或低成本云实例)。“最好”适2026年5月11日 -

新加坡网站服务器:高性能、稳定的选择
新加坡网站服务器:高性能、稳定的选择 在选择网络托管服务时,新加坡网站服务器是一个备受推崇的选择。新加坡作为东南亚的商业中心,拥有完善的基础设施和稳定的网络环境,为网站提供了高性能和稳定的服务。 新加坡网站服务器采用先进的硬件设备和优化的软件配置,确保网站能够快速响应用户请求。无论是网页加载速度还是数据传输速度,都能够达到较高2025年6月26日 -

新加坡服务器的最佳选择
新加坡服务器的最佳选择 在当今数字化时代,服务器的选择对于企业和个人网站至关重要。新加坡作为亚洲最重要的技术和商业中心之一,拥有先进的基础设施和优越的地理位置,成为许多企业寻求服务器托管和云计算服务的首选地点。 新加坡位于东南亚,地理位置独特,连接着亚洲的东西方。这使2025年4月6日